
Structuring Social Data for AI

Why we built this
Aquin already had the training side covered. data calibration ran continuously during fine-tuning runs, keeping the training and eval distributions aligned. regression tracking caught behavior drift step by step, comparing the fine-tuned model against a frozen baseline on held-out prompts. Signals fired when gradient norms spiked, when loss curves stalled, when weight norms moved unexpectedly.
What we didn't have was the earlier layer. The training monitor could tell you a run was going sideways, but it couldn't tell you whether the data going into that run was clean in the first place. A model trained on injected data can look perfectly healthy on loss curves all the way to the end. Toxicity doesn't show up in gradient norms. PII doesn't appear in weight statistics. The problem is upstream of anything the training monitor sees.
So we went back to the data. Not to sample it manually — that misses the systematic — but to build a module that runs a structured analysis at the row and column level across every dimension we care about: attack surface, privacy, quality, compliance. The same rigor we applied to monitoring what happens during training, applied to inspecting what goes into it.
That's the Data Inspection System. It plugs in before the training run starts, produces an audit trail, and hands the training monitor a dataset it can be confident about.
Open-sourcing the Data Inspection System
We're open-sourcing Aquin's Data Inspection System. It runs fully offline, on average laptops, on CPUs. No cloud dependency required. Pair it with Ollama and the entire pipeline runs locally, with no data leaving the machine.
Most dataset investigations stop at the sample: pull a hundred rows, eyeball the distribution, move on. What that misses is the systematic — the 6% of rows carrying toxicity signals, the SSNs concentrated in one column, the 33% of data tracing back to model-generated sources, the four rows seeded with instruction-override patterns, the trigger phrases that shift model behavior on cue. The inspection system runs a full eleven-module analysis on any dataset you can load, at the row and column level, and produces a complete audit trail of everything it found.
Load a dataset from HuggingFace by ID, or upload a CSV, JSONL, or Parquet file directly. Every ingestion records source, timestamp, and a file hash as the first entry in the audit trail.
What it checks
Each module answers a question the others can't. They chain: a high near-duplicate rate triggers synthetic detection; elevated PII density triggers liability chain tracing on those columns; synthetic and poisoned sample findings feed the integrity group together. Three modules focus specifically on attack surface — prompt injection patterns seeded in training data, poisoned samples designed to corrupt model behavior, and backdoor trigger phrases that activate on cue.
Offline and local
The system is designed to run on the hardware you already have. Every module runs on CPU. On an average laptop, a 5,000-row dataset completes a full eleven-module pass in under two minutes. Pair it with Ollama to swap in locally hosted models for the LLM-dependent checks, and nothing leaves the machine at any point in the pipeline.
This matters for teams working with sensitive datasets that can't be sent to external APIs — medical records, legal documents, proprietary research corpora. The full audit trail, including SHA-256 sealed output, is generated and exported locally.
Case study: Vivly × Aquin
This case study details the pipeline of extracting, structuring, and validating public sentiment data surrounding privacy and safety concerns related to AI-powered wearable devices. Discussions around Meta Ray-Ban smart glasses intensified in early 2026 as users, researchers, and online communities debated issues such as surveillance, consent, data collection, and transparency in AI training practices.
To analyze this broader conversation, the project integrated Vivly to autonomously identify signals and Aquin to rigorously inspect the dataset. While the retrieval pipeline surfaced a much larger corpus of wearable AI and privacy-related discussions, this case study specifically focuses on conversations related to Meta Ray-Ban smart glasses. The final result is a curated 1,500-entry training dataset sourced from Reddit and Hacker News that captures public discussions around consumer trust, privacy expectations, passive recording concerns, and AI-enabled wearable technology.
Background
The dataset was collected during a period of heightened public discussion around privacy practices associated with Meta Ray-Ban glasses. Conversations across online communities focused on topics such as passive recording, AI training transparency, third-party data handling, and how wearable AI devices may affect expectations of privacy in public and personal spaces.
One incident that intensified these discussions involved investigative reports alleging that contractors associated with AI data labeling operations reviewed user-generated video and audio clips captured through the glasses. The reports raised broader concerns around informed consent, transparency in AI training workflows, data handling practices, and the privacy implications of wearable AI systems.
Following public backlash and regulatory scrutiny, Meta reportedly paused and later ended parts of its collaboration with Sama, a Kenya-based data annotation company involved in the workflow. The controversy also contributed to public debate around AI governance, consumer trust, and responsible deployment of always-on wearable technologies.
Architecture
Vivly handled source discovery and structuring. Aquin's Dataset Inspector handled the final validation and compliance pass. Each tool played to its strengths, and the handoffs between them were clean.
Vivly is a signal identification platform for public and social data. It surfaces meaningful signals from large-scale discussions, helping enterprises understand exactly what is being discussed, by whom, and why it matters. The project used the Vivly SDK, available via pip and npm, to fetch relevant discussions around the Meta Ray-Ban privacy controversy.
Because the dataset contained raw internet reactions to a highly sensitive privacy controversy, it required thorough sanitization before being used for training and analysis.
Data preparation
To capture authentic public reactions to Meta Ray-Ban smart glasses, data was sourced from Reddit and Hacker News — platforms hosting some of the most unfiltered debates on emerging tech and privacy. The following query was passed to the Vivly SDK:
vivly SDK query
vivly route \
"Meta Ray-Ban wearable AI privacy discussions and recording concerns" \
--reddit --hackernews \
--items=1500 --format=jsonlUsing the Vivly SDK, the pipeline initially surfaced several thousand public discussions across Reddit and Hacker News related to wearable AI, privacy expectations, surveillance concerns, and Meta Ray-Ban smart glasses. After multiple filtering and validation stages designed to remove noise, duplicates, and low-relevance entries, the dataset was refined into a curated corpus of 1,500 high-signal discussions for downstream analysis and experimentation.
The SDK analysed the intent, identified specific communities actively discussing it, and interfaced with the Reddit and Hacker News APIs to fetch discussions by matching relevant keywords. Raw output was passed through Vivly's noise-to-signal module, leaving only high-value, relevant conversations focused on the core themes.
raw entry structure · JSON
{
"id": "1stq3ct",
"url": "https://www.reddit.com/r/privacy/comments/1stq3ct/...",
"score": 479,
"title": "Being recorded with meta glasses during work",
"content": "Today I was doing my job at a restaurant...",
"subreddit": "privacy",
"created_date": "2026-04-23T17:51:33+00:00",
"num_comments": 227,
"comments": [
{
"id": "ohv9lnq",
"body": "Mention it to bosses as it has to be addressed in some standard
yet inoffensive way for staff — that you can politely decline to
be recorded more than a couple of seconds, say.",
"score": 351,
"depth": 0,
"created_utc": 1776968911.0
}
]
}Data processing
The raw JSON data extracted from Reddit and Hacker News was deeply valuable but far too unstructured for direct model training
The key step here was using Claude Sonnet 4.6 not to generate content, but to restructure it.
The model analyzed the raw data and logically grouped scattered discussions based on shared article links and core topics. This preserved the contextual richness of the human conversations while organizing them into coherent, unified threads.
This consolidation step compressed approximately 1,500 individual discussions into 296 structured conversational rows while preserving the core semantic context and sentiment patterns present across the source material. The resulting structure was significantly more efficient for downstream inspection, clustering, and compliance analysis.
Once the discussions were logically grouped, the data was passed through a lightweight formatting script. This step required no additional AI processing. The script converted the grouped data into a strict, LLaMA-compatible prompt-and-answer format. The output was a clean JSON Lines (JSONL) file structured to match the ingestion requirements of Aquin's Dataset Inspector.
Finally, the formatted JSONL file was uploaded into Aquin, where the Dataset Inspector automatically processed the entries through its predefined evaluation pipelines.
Inspection results
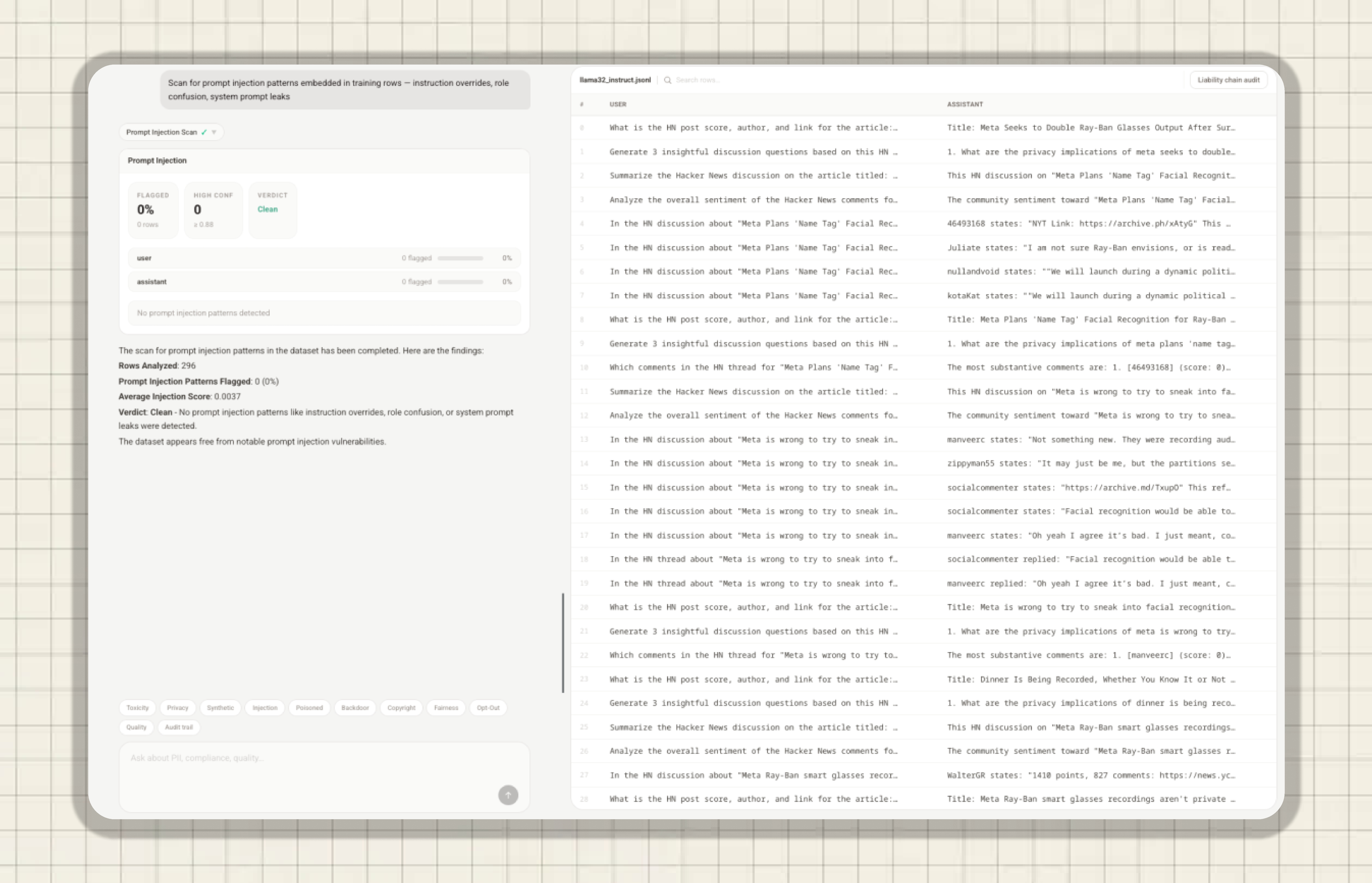
Scans the dataset's training rows to detect embedded prompt injection patterns — inputs designed to hijack the AI by overriding its primary instructions. The dataset was analyzed across 296 rows and returned a completely clean verdict. Zero rows were flagged, and the average injection score was an extremely low 0.0037.
Checks any web links present in the dataset against the Spawning AI opt-out registry and standard robots.txt restrictions, ensuring the data respects creator consent and legal scraping boundaries. The scanner detected zero URL columns in this dataset — no domains were blocked and no further opt-out compliance checks were required.
Detects protected attributes — such as gender, race, or age — and measures label imbalances to ensure the dataset is fair and won't train the AI to exhibit discriminatory behavior. Bias risk was marked as low. The system detected zero protected attributes and zero label columns across the 296 rows.
Evaluates the dataset for harmful, offensive, or inappropriate language, providing a severity breakdown and pinning the worst offenders for manual review. The overall verdict was clean. While 4.7% of the data (14 rows) was flagged for minor toxicity, only 1 row was classified as severe (scoring ≥ 0.8). The vast majority of the sample remains safe.
A deeper injection scan targeting adversarial attacks that attempt to cause role confusion or trick the AI into leaking its confidential backend system prompts. Just like the primary injection scan, this came back clean — a 0% flag rate for advanced manipulation tactics in both the user and assistant columns.
Analyzes text to determine if it was generated by an AI rather than written by a human, scoring the likelihood of AI origin and pinpointing suspect rows. The overall dataset is classified as human, with a low average synthetic score of 0.1432. However, 0.7% of the data (2 rows) was flagged as highly synthetic: Row #178 (assistant) hit 100% synthetic confidence, and Row #138 (user) hit 90% confidence.
Detects maliciously altered training samples by searching for cluster outliers, label inconsistencies, and loss anomaly signals. Across all 296 rows, the dataset performed with a 0% flagged rate and a clean verdict. No cluster outliers, label inconsistencies, or loss anomalies were found, and the average anomaly score remained extremely low at 0.1423.
Evaluates potential intellectual property violations by calculating a composite IP score based on domain analysis, inline license signals, and copyrighted content markers. This returned an elevated overall risk with a composite score of 46 out of 100 — driven entirely by the absence of a declared license, which caused the system to assume a restricted status and generate a high license risk score of 75. The actual content analysis posed very low risk (0.0125), with 0% copyright notices, open license references, or book markers found.
Combs through the dataset to identify Personally Identifiable Information such as names, emails, phone numbers, and locations. This scan resulted in a high risk verdict. The system found that 30.4% of the dataset (90 out of 296 rows) contains PII, detecting 106 specific entities — 105 flagged as sensitive (Nationality/Religion, medium risk) and 1 flagged as contact (a phone number, high risk).
Evaluates foundational text quality by analyzing language distribution and scanning for exact or near-duplicate rows. The dataset showed exceptional text hygiene — 100% English with no mixed-language anomalies. Duplicate detection (using a 0.85 Jaccard similarity threshold) confirmed that 100% of the 296 rows are clean, with 0% near-duplicates and 0 exact identical rows.
Grades the dataset's privacy and security metrics against established regulatory frameworks. The dataset received an overall health score of 40 out of 100. Of 5 clauses assessed, 4 failed and 1 passed. Failures were tied to the PII discovered in the previous scan — failing Article 10(3), Section 4 (Lawful basis for processing), NIST AI RMF MAP 2.2, and MANAGE 3.1. It successfully passed Section 9 (Sensitive Personal Data) due to the absence of hyper-sensitive identifiers.
Summarizes audit findings into definitive framework scores and outputs a structured remediation plan. Due to unmitigated PII, the dataset is currently non-compliant with the EU AI Act (score: 25%) and NIST AI RMF (score: 25%), while sitting at partial compliance with the India DPDPA (score: 62%). The remediation plan requires: data minimization and anonymization targeting the exposed phone number; aligning processing activities with lawful bases; and implementing continuous monitoring as the dataset grows.
Structuring social data
Public social data is inherently messy. Reddit threads branch, Hacker News comment chains nest four levels deep, the same article surfaces across a dozen subreddits with completely different reactions. The raw API output is a graph, not a dataset.
What Vivly's noise-to-signal module does is collapse that graph into a set of coherent conversations grouped by intent. What Claude's restructuring pass does is reformat those conversations into training-compatible prompt-and-answer pairs without generating any new content. The structured dataset preserves the actual human signal — the skepticism, the privacy concerns, the first-person accounts — in a form a model can learn from.
The inspection layer then validates that the signal hasn't been contaminated in transit. In this case: no injection patterns, no poisoned samples, no synthetic contamination, text quality near-perfect. The one real finding was PII — 30% of rows contained nationality and religion mentions from people discussing themselves, plus a phone number. That's not a pipeline failure; it's exactly what the inspection system is for.
The pattern generalizes. Any domain where public opinion matters — product launches, policy debates, safety incidents, emerging technology adoption — has a version of this pipeline. Vivly handles source discovery and structuring. Aquin handles validation. The output is a training-ready dataset that has been inspected, documented, and is ready for remediation before a model ever sees it.
Conclusion
The inspection system worked as designed. By using Vivly to collect the discussions and Aquin to thoroughly inspect them, the team proved that the raw dataset is mostly secure and of very high quality. The text is free from AI manipulation, harmful bias, and poisoned samples, making it an excellent starting point for understanding real human concerns about wearable AI.
The final safety checks highlighted a privacy issue that must be addressed before the data can be used. Approximately 30% of the dataset still contains PII — including a phone number and other sensitive details — causing it to fail strict legal compliance thresholds under the EU AI Act and NIST AI RMF. The immediate next step is to scrub this personal data and follow the generated remediation plan to ensure the dataset is fully safe and legally compliant.
The open-source inspector is available now. It runs offline, on CPU, with Ollama support for teams that need everything local.